
A processing task triggers the execution of a run executable.
The run executable reads the inputs via the stdin channel as if one would do:
$ echo "file1\nfile2" | myExecutable
This section defines typical design patterns which include:
There are two standard design patterns:
And there auxiliary nodes that do not process the inputs but arrange and/or combine them for subsequent nodes in the workflow.
This design pattern processes inputs independently from one another. There will several processing task processing a number of inputs each.
The typical structure of such a run executable is:
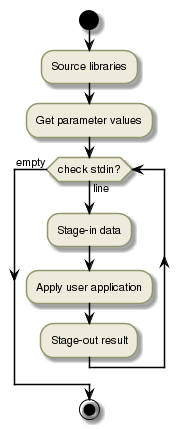
Below you find templates implementing this design pattern:
This design pattern processes all inputs to generate the result. There will one single processing task processing all the inputs.
The typical structure of such a run executable is:
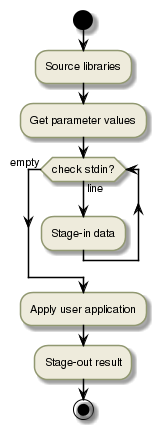
Auxiliary nodes are needed when the output of a node cannot be directly processed by the subsequent nodes (e.g. parallel processing would not be possible).
These nodes usually process the data by reference (no stage-in) and combines or arranges these references and provides those references as outputs.
Typical examples are: