In this exercise we will prepare input data for our workflow (this process is named Stage In), and we will publish out data as result of the workflow (this process is named Stage Out).
cd
cd dcs-hands-on
mvn clean install -D hands.on=3 -P bash
The application.xml is similar to the one used in the first hands-on exercise a basic workflow:
<?xml version="1.0" encoding="us-ascii"?>
<application xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" id="my_application">
<jobTemplates>
<jobTemplate id="my_template">
<streamingExecutable>/application/my_node/run</streamingExecutable>
</jobTemplate>
</jobTemplates>
<workflow id="hands-on-3" title="Staging Data" abstract="Exercise 3, staging data">
<workflowVersion>1.0</workflowVersion>
<node id="my_node">
<job id="my_template"/>
<sources>
<source refid="file:urls">/application/inputs/list</source>
</sources>
</node>
</workflow>
</application>
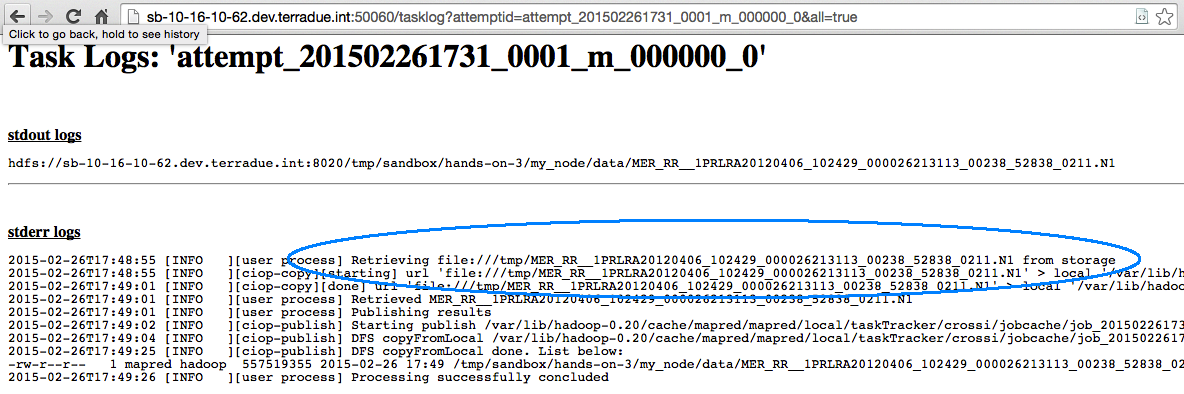
We need a local copy of the data to be ingested by a run executable. We can use the ciop-copy tool to interact with a remote catalogue, retrieve a data source (download link) from its catalogue reference, and download the data locally.
cd /tmp
opensearch-client https://catalog.terradue.com/eo-samples/series/mer_rr__1p/search?uid=MER_RR__1PRLRA20120407_112751_000026243113_00253_52853_0364 enclosure | ciop-copy -o /tmp -
opensearch-client https://catalog.terradue.com/eo-samples/series/mer_rr__1p/search?uid=MER_RR__1PRLRA20120406_102429_000026213113_00238_52838_0211 enclosure | ciop-copy -o /tmp -
ls -l | grep MER_RR
The output of the ls -l command will be similar to:
total 1091164
-rw-r--r-- 1 crossi ciop 558118134 Apr 24 17:41 MER_RR__1PRLRA20120406_102429_000026213113_00238_52838_0211.N1
-rw-r--r-- 1 crossi ciop 558118134 Apr 24 17:35 MER_RR__1PRLRA20120407_112751_000026243113_00253_52853_0364.N1
file:///tmp/MER_RR__1PRLRA20120406_102429_000026213113_00238_52838_0211.N1
file:///tmp/MER_RR__1PRLRA20120407_112751_000026243113_00253_52853_0364.N1
These lines define the input data to be ingested by a run executable.
Warning
The file inputs/list should contain only these two lines (without blank lines or comments).
cd $_CIOP_APPLICATION_PATH
more my_node/run
Several programming or scripting languages are supported to implement the run executable. In the above example we used bash.
ciop-publish $TMPDIR/*.N1
Note
The command ciop-publish will put the workflow’s stage out data on the HDFS (the underlying Hadoop Distributed File System), and it will pass it to the Hadoop framework by reference.
ciop-run my_node
The output will be similar to:
2016-01-19 12:54:32 [WARN ] - -- WPS needs at least one input value from your application.xml (source or parameter with scope=runtime);
2016-01-19 12:54:33 [INFO ] - Workflow submitted
2016-01-19 12:54:33 [INFO ] - Closing this program will not stop the job.
2016-01-19 12:54:33 [INFO ] - To kill this job type:
2016-01-19 12:54:33 [INFO ] - ciop-stop 0000005-160119102214227-oozie-oozi-W
2016-01-19 12:54:33 [INFO ] - Tracking URL:
2016-01-19 12:54:33 [INFO ] - http://sb-10-16-10-50.dev.terradue.int:11000/oozie/?job=0000005-160119102214227-oozie-oozi-W
Node Name : my_node
Status : OK
Publishing results...
2016-01-19 12:56:12 [INFO ] - Workflow completed.