Data publication operations¶
One of the main motivations behind the Ellip platform is to share results and make them available to others. Some work is necessary to achieve that, and we distinguish three steps that form the process of data publication:
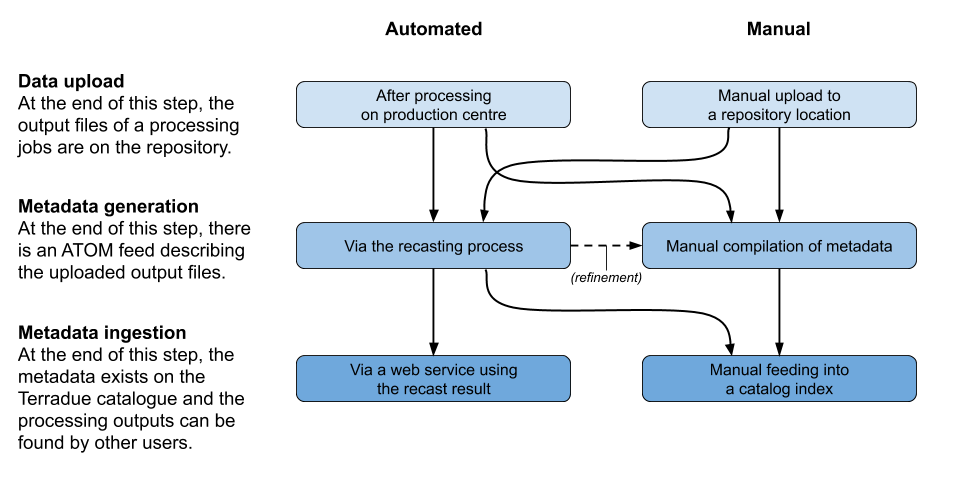
- Data upload: In this step, the result files of a process are uploaded on a repository to make it available for other users.
- Metadata generation: In this step, the result files are analysed, and metadata, such as spatial and temporal coverage, is extracted and made available on an internal metadata catalog. Data is analysed and some elements (especially map layers) can be rendered and uploaded in addition to the previously uploaded content. Besides the many properties and characteristics that describe the produced results, the metadata must contain the correct links to the actual files that compose them and that were uploaded in the previous step.
- Metadata ingestion: This final operation feeds the metadata record of a result into the metadata catalog (on private or public indices). Only at that point, with the metadata in a catalog index, the produced results are fully available to others (authorised users or everybody) because now they can be found via their metadata.
The following image gives an overview of the various ways in which data can be published. The sections that follow below explain them in more detail.
Note
In the last section (Sample scenarios), you will find several Jupyter notebooks that show how all these steps can be perfomed using the Python programming language. These notebooks will help you understand better certain aspects of the publication by experimenting directly with the code and seeing the effects of the various operations.